| Title: | Item Analysis for Multiple Choice Tests |
| Version: | 3.1.1 |
| Description: | Functions for analyzing multiple choice items. These analyses include the convertion of student response into binaty data (correct/incorrect), the computation of the number of corrected responses and grade for each subject, the calculation of item difficulty and discrimination, the computation of the frecuency and point-biserial correlation for each distractor and the graphical analysis of each item. |
| License: | MIT + file LICENSE |
| URL: | https://github.com/arielarmijo/itan |
| BugReports: | https://github.com/arielarmijo/itan/issues |
| Depends: | R (≥ 2.10) |
| Imports: | ggplot2, reshape |
| Language: | es |
| Encoding: | UTF-8 |
| RoxygenNote: | 7.1.2 |
| LazyData: | true |
| Suggests: | rmarkdown, knitr, testthat (≥ 3.0.0), readxl |
| Config/testthat/edition: | 3 |
| VignetteBuilder: | knitr |
| NeedsCompilation: | no |
| Packaged: | 2022-02-10 13:16:15 UTC; aarmijo |
| Author: | Ariel Armijo [aut, cre] |
| Maintainer: | Ariel Armijo <arielarmijo@yahoo.es> |
| Repository: | CRAN |
| Date/Publication: | 2022-02-10 13:40:06 UTC |
Análisis gráfico de ítems.
Description
El análisis gráfico de ítems (agi) permite visualizar las alternativas que eligen los estudiantes según su desempeño general en la prueba. El agi proporciona información esencial y fácilmente interpretable acerca de características técnicas del ítem tales como su dificultad y poder de discriminación.
Usage
agi(respuestas, clave, alternativas, nGrupos = 4, digitos = 2)
Arguments
respuestas |
Un data frame con las alternativas seleccionadas por los estudiantes en cada ítem de la prueba. |
clave |
Un data frame con las alternativas correctas para cada ítem. |
alternativas |
Un vector con las alternativas posibles para cada ítem. |
nGrupos |
Número de grupos en los que se categorizarán los estudiantes según el puntaje obtenido en la prueba. |
digitos |
La cantidad de dígitos significativos que tendrá el resultado. |
Details
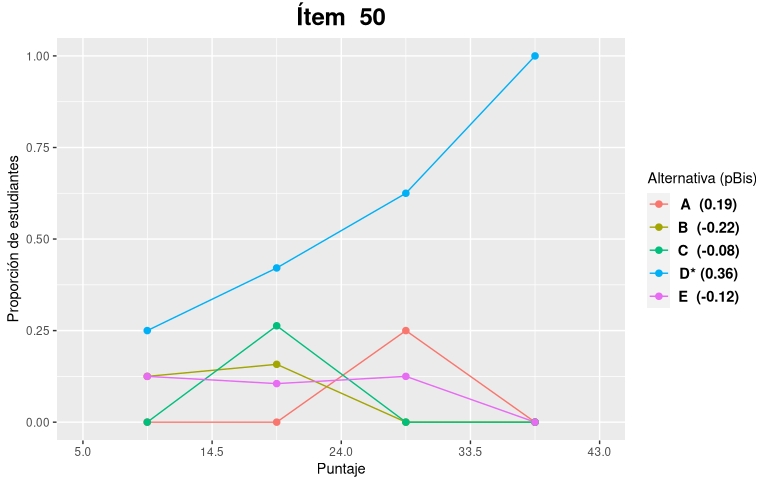
Los estudiantes se clasifican habitualmente en 4 categorías según su puntaje alcanzado en la prueba. La proporción de estudiantes de cada grupo que seleccionó una alternativa determinada se muestra en el eje Y. Por ejemplo, en la siguiente figura se puede observar que todos los estudiantes del grupo 4 (mejor desempeño) seleccionaron la alternativa correcta D, mientras que el 25% de los estudiantes del grupo 1 (peor desempeño) seleccionaron esta opción.
Value
Una lista en la que cada elemento corresponde a un ítem de la prueba. Cada elemento de la lista contiene a su vez una lista con dos elementos. El primero de ellos corresponde a los datos; mientras que el segundo, al gráfico.
References
Guadalupe de los Santos (2010). Manual para el análisis gráfico de ítems. Universidad Autónoma de Baja California. Recuperado de manual_pagi.pdf
Examples
respuestas <- datos[,-1]
alternativas <- LETTERS[1:5]
item <- agi(respuestas, clave, alternativas)
item$i01$datos
item$i01$plot
item$i25$datos
item$i25$plot
item$i50$datos
item$i50$plot
Análisis de alternativas
Description
Calcula la frecuencia o proporción de las alternativas seleccionadas por el grupo superior e inferior de estudiantes en cada ítem.
Usage
analizarAlternativas(respuestas, clave, alternativas, proporcion = 0.25)
Arguments
respuestas |
Un data frame con las alternativas seleccionadas por los estudiantes en cada ítem. |
clave |
Un data frame con las alternativas correctas para cada ítem. |
alternativas |
Un vector con las alternativas posibles para cada ítem. |
proporcion |
Proporción del total de estudiantes que constituyen los grupos superior e inferior. |
Value
Una lista en la cual cada elemento corresponde a un ítem. Para cada ítem se calcula la frecuencia o proporción de las alternativas seleccionadas por el grupo superior y por el grupo inferior de estudiantes.
References
Morales, P. (2009). Análisis de ítem en las pruebas objetivas. Madrid. Recuperado de https://educrea.cl/wp-content/uploads/2014/11/19-nov-analisis-de-items-en-las-pruebas-objetivas.pdf
See Also
calcularFrecuenciaAlternativas, datos y clave.
Examples
respuestas <- datos[,-1]
alternativas <- LETTERS[1:5]
analizarAlternativas(respuestas, clave, alternativas)
Frecuencia de alternativas
Description
Calcula la frecuencia o proporcion de las alternativas seleccionadas en cada ítem.
Usage
calcularFrecuenciaAlternativas(
respuestas,
alternativas,
clave = NULL,
frecuencia = FALSE,
digitos = 2
)
Arguments
respuestas |
Un data frame con las respuestas corregidas de los estudiantes. |
alternativas |
Un vector con las alternativas posibles como respuestas. |
clave |
Un data frame con las respuestas correctas a cada pregunta. |
frecuencia |
Un valor lógico que determina si la información
se presenta como frecuencia ( |
digitos |
La cantidad de dígitos significativos que tendrá el resultado. |
Value
Un data frame con los ítems como filas y las frecuencias de las alternativas como columnas. Si está presente la clave como parámetro, se agrega la alternativa correcta como columna.
See Also
corregirRespuestas, datos y
clave.
Examples
alternativas <- c("A", "B", "C", "D", "E", "*")
respuestas <- datos[,-1]
calcularFrecuenciaAlternativas(respuestas, alternativas, clave, frecuencia=TRUE)
Índice de dificultad
Description
Calcula el índice de dificultad para cada ítem.
Usage
calcularIndiceDificultad(respuestasCorregidas, proporcion = 0.5, digitos = 2)
Arguments
respuestasCorregidas |
Un data frame con los puntajes obtenidos por los estudiantes en cada pregunta. |
proporcion |
Proporción de estudiantes que forman parte de los grupos superior e inferior. Valores habituales son 0.25, 0.27 y 0.33. Una proporción de 0.5 significa que se toman todos los datos para calcular este índice. |
digitos |
La cantidad de dígitos significativos que tendrá el resultado. |
Details
El índice de dificultad p corresponde a la proporción de estudiantes de los grupos superior e inferior que responden correctamente el ítem. Puede tomar valores entre 0 y 1. A mayor valor, el ítem es más fácil y viceversa.
Value
Una vector con los índices de dificultad para cada ítem.
References
Morales, P. (2009). Análisis de ítem en las pruebas objetivas. Madrid. Recuperado de https://educrea.cl/wp-content/uploads/2014/11/19-nov-analisis-de-items-en-las-pruebas-objetivas.pdf
See Also
corregirRespuestas, datos y clave.
Examples
respuestas <- datos[,-1]
respuestasCorregidas <- corregirRespuestas(respuestas, clave)
p <- calcularIndiceDificultad(respuestasCorregidas)
item <- colnames(respuestas)
cbind(item, p)
Índice de discriminación
Description
Calcula el índice de discriminación para cada ítem.
Usage
calcularIndiceDiscriminacion(
respuestasCorregidas,
tipo = "dc1",
proporcion = 0.27,
digitos = 2
)
Arguments
respuestasCorregidas |
Un data frame con los puntajes obtenidos por los estudiantes en cada pregunta. |
tipo |
Una cadena de texto que indica el tipo de índice de discriminación a calcular. Valores posibles son: "dc1" o "dc2" |
proporcion |
Proporción de estudiantes que forman parte de los grupos superior e inferior. Valores habituales son 0.25, 0.27 y 0.33. |
digitos |
La cantidad de dígitos significativos que tendrá el resultado. |
Details
Los índices de discriminación permiten determinar si un ítem diferencia entre estudiantes con alta o baja habilidad. Se calculan a partir del grupo de estudiantes con mejor y peor puntuación en el test.
El índice de discriminación 1 (dc1) corresponde a la diferencia entre la proporción de aciertos del grupo superior y la proporción de aciertos del grupo inferior. Los valores extremos que puede alcanzar este índice son 0 y +/-1. Los ítems con discriminación negativa favorecen a los estudiantes con baja puntuación en el test y en principio deben ser revisados. Este índice se ve influenciado por el índice de dificultad, por lo que a veces es conveniente compararlo con el índice de discriminación 2 (dc2).
El índice de discriminación 2 (dc2) corresponde a la proporción de aciertos del grupo superior en relación al total de aciertos de ambos grupos. Los valores de este índice van de 0 a 1. Pueden considerarse satisfactorios valores mayores a 0.5. Este índice es independiente del nivel de dificultad de la pregunta.
Value
Un vector con el índice de discriminación para cada ítem.
References
Morales, P. (2009). Análisis de ítem en las pruebas objetivas. Madrid. Recuperado de https://educrea.cl/wp-content/uploads/2014/11/19-nov-analisis-de-items-en-las-pruebas-objetivas.pdf
See Also
corregirRespuestas, calcularIndiceDificultad, datos y clave.
Examples
respuestas <- datos[,-1]
respuestasCorregidas <- corregirRespuestas(respuestas, clave)
dc1 <- calcularIndiceDiscriminacion(respuestasCorregidas, tipo="dc1", proporcion=0.25)
dc2 <- calcularIndiceDiscriminacion(respuestasCorregidas, tipo="dc2", proporcion=0.25)
p <- calcularIndiceDificultad(respuestasCorregidas, proporcion=0.25)
cbind(p, dc1, dc2)
Cálculo de notas
Description
Calcula la nota obtenida por cada estudiante en función de su puntaje alcanzado en la prueba. Se utiliza el sistema de calificación utilizado en Chile.
Usage
calcularNotas(
puntajes,
pjeMax = max(puntajes),
notaMin = 1,
notaMax = 7,
notaAprobacion = 4,
prema = 0.6
)
Arguments
puntajes |
Un data frame con los puntajes obtenidos por los estudiantes en la prueba. |
pjeMax |
El puntaje máximo posible de alcanzar en la prueba. |
notaMin |
La nota mínima otorgada al estudiante sin puntaje. |
notaMax |
La nota máxima otorgada al estudiante con mejor puntaje. |
notaAprobacion |
La nota necesaria para aprobar la prueba. |
prema |
Porcentaje de rendimiento mínimo aceptable. Corresponde a la proporción del puntaje máximo necesario para obtener la nota de aprobación en la prueba. |
Value
Un data frame con las notas obtenidas por los estudiantes en la prueba.
References
Pumarino, J. Escala de notas: Explicación de fórmula general y cálculo específico. Recuperado de https://escaladenotas.cl/?nmin=1.0&nmax=7.0&napr=4.0&exig=60.0&pmax=100.0&explicacion=1
See Also
corregirRespuestas, calcularPuntajes,
datos y clave.
Examples
respuestas <- datos[,-1]
respuestasCorregidas <- corregirRespuestas(respuestas, clave)
puntaje <- calcularPuntajes(respuestasCorregidas)
nota <- calcularNotas(puntaje)
cbind(id=datos[1], puntaje, nota)
Cálculo de puntajes
Description
Calcula el puntaje total obtenido en la prueba por cada estudiante.
Usage
calcularPuntajes(respuestasCorregidas)
Arguments
respuestasCorregidas |
Un data frame con el puntaje obtenido por los estudiantes en cada ítem. |
Value
Un vector con el puntaje total obtenido en la pruebas por cada estudiante.
See Also
corregirRespuestas, datos y clave.
Examples
respuestas <- datos[,-1]
respuestasCorregidas <- corregirRespuestas(respuestas, clave)
puntajes <- calcularPuntajes(respuestasCorregidas)
cbind(id=datos[1], puntaje=puntajes)
Respuestas correctas a los ítems del test
Description
Un data frame con las respuestas correctas a los ítems del test.
Usage
clave
Format
Data frame con 1 observación y 50 variables:
- i01
Alternativa correcta para la pregunta 1.
- i02
Alternativa correcta para la pregunta 2.
...
- i50
Alternativa correcta para la pregunta 50.
Corrección de respuestas
Description
La función corregir respuestas transforma las respuestas de los estudiantes
a puntaje. El puntaje puede ser un 1, si la respuesta es correcta, o un
0, si la respuesta es incorrecta. Los valores NA reciben puntaje
0.
Usage
corregirRespuestas(respuestas, clave)
Arguments
respuestas |
Un data frame con las alternativas seleccionadas por los estudiantes en cada ítem. |
clave |
Una data frame con la alternativa correcta para cada ítem. |
Value
Un data frame con los aciertos (1) o errores (0) de cada estudiante en cada ítem.
See Also
Examples
respuestas <- datos[, -1]
corregirRespuestas(respuestas, clave)
Datos de los estudiantes
Description
Un data frame con el id y las respuestas de los estudiantes. Las respuestas posibles pueden ser A, B, C, D o E. Las respuestas omitidas se representan mediante valores NA.
Usage
datos
Format
Data frame con 39 observaciones y 51 variables:
- id
Id del estudiante.
- i01
Alternativa seleccionada por el estudiante a la pregunta 1.
- i02
Alternativa seleccionada por el estudiante a la pregunta 2.
...
- i50
Alternativa seleccionada por el estudiante a la pregunta 50.
Gráfico frecuencia alternativas
Description
Grafica la frecuencia con que cada alternativa fue seleccionada por los estudiantes en cada ítem.
Usage
graficarFrecuenciaAlternativas(respuestas, alternativas, clave = NULL)
Arguments
respuestas |
Un data frame con las alternativas seleccionadas por los estudiantes en cada ítem. |
alternativas |
Un vector con las alternativas posibles como respuestas. |
clave |
(opcional) Un data frame con las alternativas correctas para cada ítem. Si se incluye este parámetro, se marcará la alternativa correcta en el eje x. |
Value
Una lista en la que cada elemento corresponde al gráfico de cada ítem.
See Also
Examples
alternativas <- c(LETTERS[1:5], "*")
respuestas <- datos[,-1]
grafico <- graficarFrecuenciaAlternativas(respuestas, alternativas, clave)
grafico$i01
grafico$i025
grafico$i025
itan: Paquete para el análisis de ítems de pruebas objetivas
Description
El paquete itan incluye funciones que permiten calcular el puntaje y calificación obtenido por estudiantes en una prueba objetiva. Además, incorpora funciones para analizar los ítems del test y sus distractores. Entre estos últimos destaca el análisis gráfico de ítems que permite visualizar las características técnicas del ítem y determinar rápidamente su calidad.
Details
El paquete itan incluye datos para probar las funciones del paquete.
El data frame datos contiene las respuestas seleccionadas
por 39 estudiantes en una prueba objetiva de 50 ítems de selección múltiple.
Las alternativas posibles a cada ítem son 'A', 'B', 'C', 'D' y 'E', mientras
que las respuestas omitidas se indican mediante un '*'.
Cada estudiante tiene asociado un id único que figura en la columna 1 del data
frame. Las columnas que representan los ítems están rotuladas como 'i01',
'i02', ..., 'i50'.
Por otro lado, el data frame clave contiene las alternativas
correctas para cada ítem de la prueba.
Funciones del paquete itan
La función corregirRespuestas permite determinar si las alternativas
seleccionadas por los estudiantes son correctas o incorrectas. Se asigna un 1
si la respuesta es correcta y un 0 si es incorrecta. El data frame con valores
binarios devuelto por esta función puede ser utilizado por la función
calcularPuntajes para determinar el puntaje obtenido en la prueba.
A partir de los puntajes obtenidos en la prueba se puede calcular la calificación
de cada estudiante con la función calcularNotas. Esta última función
utiliza el sistema de calificación usado en Chile:
notas de 1.0 a 7.0, con nota de aprobación 4.0 y nivel de exigencia del 60\
El data frame binario devuelto por la función corregirRespuestas
también puede ser usado para calcular el índice de dificultad y dos tipos de
índices de discriminación. Estas funciones son calcularIndiceDificultad
y calcularIndiceDiscriminacion, respectivamente.
Las respuestas de los estudiantes sin procesar, junto con la clave de corrección,
pueden utilizarse para hacer dos tipos de análisis de distractores con las funciones
calcularFrecuenciaAlternativas y analizarAlternativas.
También se puede calcular la correlación biserial puntual de cada alternativa
con respecto al puntaje obtenido en la prueba con la función pBis.
Por último, con la función agi se puede analizar gráficamente la
frecuencia de estudiantes que seleccionó cada alternativa en función de su
desempeño en la prueba. Esta función devuelve una lista con los datos y gráficos
generados para cada ítem. La inspección de las gráficas permite rápidamente determinar
la calidad del ítem.
References
Morales, P. (2009). Análisis de ítem en las pruebas objetivas. Madrid. Recuperado de análisis de ítems
Guadalupe de los Santos (2010). Manual para el análisis gráfico de ítems. Universidad Autónoma de Baja California. Recuperado de manual_pagi.pdf
Correlación biserial puntual.
Description
Calcula la correlación biserial puntual para cada alternativa en cada ítem con respecto al puntaje obtenido en la prueba.
Usage
pBis(respuestas, clave, alternativas, correccionPje = TRUE, digitos = 2)
Arguments
respuestas |
Un data frame con las alternativas seleccionadas por los estudiantes a cada ítem de la prueba. |
clave |
Un data frame con la alternativa correcta para cada ítem. |
alternativas |
Un vector con las alternativas posibles para cada ítem. |
correccionPje |
Un valor lógico para usar o no la corrección de puntaje. La corrección de puntaje consiste en restar del puntaje total el punto obtenido por el ítem analizado. |
digitos |
La cantidad de dígitos significativos que tendrá el resultado. |
Details
Para su cálculo se utiliza la siguiente ecuación:
r_{bp} = \frac{\overline{X_{p}}-\overline{X_{q}}}{\sigma_{X}}\sqrt{p \cdot q}
Value
Un data frame con la correlación biserial puntual para cada alternativa en cada ítem.
References
Attorresi, H, Galibert, M. y Aguerri, M. (1999). Valoración de los ejercicios en las pruebas de rendimiento escolar. Educación Matemática. Vol. 11 No. 3, pp. 104-119. Recuperado de http://www.revista-educacion-matematica.org.mx/descargas/Vol11/3/10Attorresi.pdf
See Also
analizarAlternativas, calcularFrecuenciaAlternativas
datos y clave.
Examples
respuestas <- datos[, -1]
alternativas <- LETTERS[1:5]
pBis(respuestas, clave, alternativas)